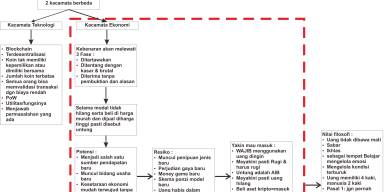
Apa itu Quantization pada model AI, apa arti Q 0 K M

Apa itu Quantization (kuantisasi) ?
Quantization (kuantisasi) dalam konteks model AI adalah proses mengubah representasi numerik dari bobot dan aktivasi model dari presisi tinggi (misalnya float32 atau float16) menjadi format presisi lebih rendah (misalnya int8, int4, bahkan int2). Tujuannya adalah untuk:
? Tujuan Quantization
- Mengurangi ukuran model
Format presisi rendah jauh lebih ringkas. Misalnya:- float32: 32 bit
- int8: hanya 8 bit (1/4 ukuran float32)
- float32: 32 bit
- Mempercepat inferensi
Operasi matematika menggunakan tipe data lebih kecil dapat dihitung lebih cepat, terutama di CPU dan edge devices (seperti Raspberry Pi, Orange Pi, atau ponsel). - Mengurangi kebutuhan memori (RAM/VRAM)
Dengan data lebih kecil, kita bisa memuat model besar ke perangkat dengan kapasitas terbatas. - Menurunkan konsumsi daya
Penting untuk perangkat mobile dan IoT.
?️ Jenis-jenis Quantization
|
Nama |
Bit |
Deskripsi Singkat |
|
FP32 / FP16 |
32/16 |
Format floating point, presisi tinggi |
|
INT8 |
8 |
Format integer, umum digunakan (efisien) |
|
INT4 / INT2 |
4/2 |
Ultra-kompresi, sering dipakai untuk inference |
|
GPTQ / AWQ |
Var |
Teknik kuantisasi dengan akurasi tinggi |
|
QLoRA |
4 |
Kuantisasi untuk training efisien (LoRA) |
? Kapan Digunakan?
- Untuk fine-tuning cepat → gunakan quantization-aware training (QAT).
- Untuk inferensi lokal / deployment → gunakan post-training quantization (PTQ).
- Untuk menjalankan model besar di edge devices seperti Orange Pi, RPi, Jetson → gunakan INT4/INT8 atau format seperti GGUF.
Panduan Lengkap Quantization Model AI: Dari FP32 hingga Binary
Dalam dunia quantization (kuantisasi) model AI, terdapat beberapa varian model berdasarkan jumlah bit yang digunakan untuk menyimpan bobot dan aktivasi. Setiap varian bit ini memiliki kelebihan dan kekurangan masing-masing, terutama terkait kecepatan, ukuran model, konsumsi memori, dan akurasi.
Berikut adalah penjelasan dari yang paling umum digunakan:
? Daftar Bit-Level Quantization & Perbandingan
|
Bit |
Format Umum |
Ukuran Model |
Akurasi |
Kompatibilitas |
Cocok Untuk |
|
32 |
FP32 |
Besar |
Akurasi maksimum |
Semua perangkat |
Training utama, baseline |
|
16 |
FP16/BF16 |
Sedang |
Hampir setara |
GPU modern (A100, RTX) |
Pelatihan & inferensi presisi tinggi |
|
8 |
INT8 |
4× lebih kecil |
Turun sedikit |
CPU, GPU, TPU |
Inferensi cepat dengan akurasi baik |
|
4 |
INT4, GPTQ |
8× lebih kecil |
Turun sedang |
CPU, llama.cpp |
Edge device, inferensi lokal |
|
2 |
INT2 |
16× lebih kecil |
Turun signifikan |
Eksperimen, R&D |
Uji coba model ekstrem ringan |
|
1 |
Binary (XNOR) |
32× lebih kecil |
Jauh turun |
Khusus |
Eksperimen dalam binary NN |
? Rangkuman Tiap Bit-Level
1. FP32 (32-bit Floating Point)
- ✅ Presisi tertinggi, akurasi penuh.
- ❌ Besar & lambat, butuh banyak memori.
- ? Digunakan saat training atau baseline evaluasi.
2. FP16 / BF16 (16-bit Floating Point)
- ✅ Lebih kecil & cepat dari FP32, akurasi tetap tinggi.
- ❌ Masih terlalu besar untuk perangkat edge.
- ? Populer di pelatihan dengan GPU modern (RTX 30xx, A100).
3. INT8 (8-bit Integer)
- ✅ Ukuran model kecil (hingga 4× lebih hemat).
- ✅ Kecepatan inferensi jauh meningkat.
- ❌ Bisa menurunkan akurasi sedikit (terutama layer awal/akhir).
- ? Standar untuk deployment di CPU dan mobile (ONNX, TFLite).
4. INT4 (4-bit Integer)
- ✅ Ukuran sangat kecil (hingga 8× lebih hemat).
- ✅ Cocok untuk menjalankan model LLaMA besar di edge device.
- ❌ Akurasi turun sedang, butuh tuning atau GPTQ/AWQ.
- ? Umum digunakan di llama.cpp, GGUF, exllama.
5. INT2 / INT1 (Eksperimental)
- ✅ Ukuran & performa ekstrem (sangat hemat RAM).
- ❌ Akurasi jauh menurun, belum stabil.
- ? Untuk riset, model toy, atau jaringan binari.
⚖️ Ringkasan Plus-Minus
|
Bit |
Kelebihan |
Kekurangan |
|
FP32 |
Akurasi penuh, stabil |
Sangat boros memori dan lambat |
|
FP16 |
Lebih cepat, efisien, akurasi bagus |
Butuh GPU/CPU yang kompatibel |
|
INT8 |
Sangat efisien untuk deployment |
Akurasi bisa turun jika tidak dikalibrasi |
|
INT4 |
Ringan sekali, cocok di edge device |
Akurasi bisa turun drastis tanpa fine-tuning |
|
INT2 |
Ekstrem ringan |
Akurasi anjlok, hanya cocok untuk eksperimen |
|
INT1 |
Ukuran super kecil, teoretis |
Nyaris tidak bisa digunakan untuk model besar real |
Quantization (kuantisasi) dalam konteks model AI adalah proses mengubah representasi numerik dari bobot dan aktivasi model dari presisi tinggi (misalnya float32 atau float16) menjadi format presisi lebih rendah (misalnya int8, int4, bahkan int2). Tujuannya adalah untuk:
? Tujuan Quantization
- Mengurangi ukuran model
Format presisi rendah jauh lebih ringkas. Misalnya:- float32: 32 bit
- int8: hanya 8 bit (1/4 ukuran float32)
- float32: 32 bit
- Mempercepat inferensi
Operasi matematika menggunakan tipe data lebih kecil dapat dihitung lebih cepat, terutama di CPU dan edge devices (seperti Raspberry Pi, Orange Pi, atau ponsel). - Mengurangi kebutuhan memori (RAM/VRAM)
Dengan data lebih kecil, kita bisa memuat model besar ke perangkat dengan kapasitas terbatas. - Menurunkan konsumsi daya
Penting untuk perangkat mobile dan IoT.
?️ Jenis-jenis Quantization
|
Nama |
Bit |
Deskripsi Singkat |
|
FP32 / FP16 |
32/16 |
Format floating point, presisi tinggi |
|
INT8 |
8 |
Format integer, umum digunakan (efisien) |
|
INT4 / INT2 |
4/2 |
Ultra-kompresi, sering dipakai untuk inference |
|
GPTQ / AWQ |
Var |
Teknik kuantisasi dengan akurasi tinggi |
|
QLoRA |
4 |
Kuantisasi untuk training efisien (LoRA) |
? Kapan Digunakan?
- Untuk fine-tuning cepat → gunakan quantization-aware training (QAT).
- Untuk inferensi lokal / deployment → gunakan post-training quantization (PTQ).
- Untuk menjalankan model besar di edge devices seperti Orange Pi, RPi, Jetson → gunakan INT4/INT8 atau format seperti GGUF.
Perbedaan INT4 vs Q4: Sama Tapi Tak Serupa
✅ INT4 ≈ Q4
✅ INT8 ≈ Q8
Tapi ada sedikit nuansa teknis. Mari kita jelaskan:
? Perbandingan Q4 / Q8 vs INT4 / INT8
|
Istilah |
Makna Umum |
Catatan Teknis |
|
INT4 |
Integer 4-bit (misalnya 0–15 atau -8 hingga 7) |
Biasanya merujuk ke format data mentah |
|
Q4 |
Quantized 4-bit |
Biasanya termasuk skala + nol-titik (scale + zero-point) |
|
INT8 |
Integer 8-bit (-128 s.d. 127) |
Representasi integer murni |
|
Q8 |
Quantized 8-bit |
Bisa berarti INT8 yang sudah dikalibrasi |
? Bedanya Secara Praktis
- ✅ INT4 / INT8: Hanya tipe data — belum tentu efisien atau akurat.
- ✅ Q4 / Q8: Biasanya sudah mengalami proses quantization (misalnya dengan teknik GPTQ, AWQ, QLoRA), sehingga:
- Sudah disesuaikan (kalibrasi skala/nol).
- Dapat digunakan langsung untuk inference.
- Sudah disesuaikan (kalibrasi skala/nol).
? Contoh dari Dunia Nyata
|
Format GGUF / llama.cpp |
Artinya |
|
Q4_0, Q4_K, Q4_K_M |
Berbagai varian quantized 4-bit (INT4) |
|
Q5_1, Q5_K |
Versi 5-bit quantized |
|
Q8_0 |
Versi quantized 8-bit |
⚠️ Q4 ≠ satu jenis saja — banyak varian seperti Q4_0, Q4_K, dsb. Beberapa lebih akurat, beberapa lebih ringan.
? Kesimpulan
- ✅ INT4 = Q4 secara umum → digunakan bergantian dalam konteks AI inference.
- ⚠️ Tapi Q4 lebih spesifik → sudah melewati kalibrasi & scaling.
- ✅ Kalau kamu melihat model "Q4" di Hugging Face atau llama.cpp, itu artinya model sudah siap inferensi dalam format 4-bit.
Mengenal Q4_0 hingga Q4_K_M: Varian Kompresi 4-bit dalam Ekosistem LLM
Penamaan seperti Q4_0, Q4_K, dan Q4_K_M merujuk pada varian teknik quantization 4-bit dalam ekosistem llama.cpp dan GGUF (format model terkompresi). Setiap kode (_0, _K, _K_M) mewakili strategi yang berbeda dalam kompresi bobot dan bagaimana skala disimpan.
Berikut penjelasan detailnya:
? Struktur Penamaan: Q{bit}_{varian}
- Q4 → quantization 4-bit (artinya setiap bobot dikodekan dalam 4 bit).
- _0, _K, _K_M → teknik penyandian skala dan organisasi blok bobot.
? 1. Q4_0 (Quant 4-bit, varian 0)
- ? Teknik: Setiap blok bobot (biasanya 32 elemen) menggunakan skala tetap.
- ? Sederhana dan cepat, tetapi skema skalanya sangat kasar.
- ? Kelebihan: Paling ringan dan cepat.
- ? Kekurangan: Akurasi lebih rendah dibanding varian lain.
✅ Cocok untuk: inference lokal cepat, device sangat ringan (Orange Pi, Raspberry Pi).
? 2. Q4_K (Quant 4-bit, K untuk "k-scale" block)
- ? Teknik: Setiap blok memiliki skala dinamis per saluran (per-group) atau subblok.
- ? Lebih presisi daripada Q4_0 karena mempertimbangkan variasi distribusi nilai bobot.
- ? Kelebihan: Akurasi lebih baik dari Q4_0, masih cukup ringan.
- ? Kekurangan: Lebih berat sedikit dibanding Q4_0.
✅ Cocok untuk: inference yang membutuhkan keseimbangan antara ukuran & akurasi.
? 3. Q4_K_M (Q4_K dengan Matrix/Minimizer Extension)
- ? Teknik: Versi lanjutan dari Q4_K dengan tambahan skema minimizer untuk scaling atau pemisahan skala + offset per sub-grup.
- ? Sangat presisi untuk format 4-bit.
- ? Kelebihan: Akurasi paling tinggi untuk 4-bit.
- ? Kekurangan: Lebih berat dari Q4_K, decoding sedikit lebih kompleks.
✅ Cocok untuk: inference serius di desktop/server, saat akurasi penting.
? Perbandingan Akurasi dan Kinerja
|
Format |
Ukuran Model |
Kecepatan |
Akurasi |
|
Q4_0 |
Paling kecil |
Paling cepat |
Terendah |
|
Q4_K |
Sedang |
Cepat |
Sedang |
|
Q4_K_M |
Sedikit lebih besar |
Agak lambat |
Tertinggi di kelas 4-bit |
✅ Tips Memilih
- Pakai Q4_0 kalau kamu butuh kecepatan & ukuran minimum (cocok untuk edge device).
- Pilih Q4_K jika kamu ingin keseimbangan akurasi dan performa.
- Gunakan Q4_K_M kalau kamu peduli akurasi tinggi tapi masih mau hemat memori.
Pengaruh Quantization 4-bit terhadap Akurasi Model Bahasa Besar
Quantization, khususnya yang ekstrem seperti 4-bit, memang berpotensi memengaruhi akurasi jawaban model bahasa besar (LLM), tapi tingkat pengaruhnya tergantung beberapa faktor:
Pengaruh Quantization pada Akurasi Jawaban
- Reduksi Presisi Bobot
Quantization mengurangi bit yang digunakan untuk menyimpan bobot model (misalnya dari 16-bit float ke 4-bit integer). Ini memang bisa menyebabkan perubahan nilai bobot, sehingga model jadi "kurang presisi" dalam representasi internalnya. - Variasi Teknik Quantization
Varian seperti Q4_0 (skala tetap kasar) punya akurasi yang paling terpengaruh, sehingga model mungkin jadi kurang akurat dan kadang “miss” atau jawaban kurang tepat.
Varian lebih kompleks seperti Q4_K dan Q4_K_M memperbaiki ini dengan skala yang lebih presisi sehingga akurasinya mendekati model asli, tapi tentu trade-off-nya sedikit lebih berat secara komputasi. - Jenis Tugas
Beberapa tugas, terutama yang butuh pemahaman konteks mendalam atau reasoning rumit, lebih sensitif terhadap quantization. Tugas sederhana seperti prediksi kata atau klasifikasi mungkin masih cukup stabil. - Ukuran Model
Model yang lebih besar biasanya lebih tahan terhadap degradasi akurasi akibat quantization dibanding model kecil.
Apakah Bisa "Mis" atau Salah?
- Ya, ada kemungkinan jawaban jadi kurang tepat, tidak konsisten, atau “miss” karena error representasi bobot akibat quantization.
- Namun, varian quantization yang lebih baik (Q4_K, Q4_K_M) berusaha meminimalisir hal ini, dan untuk penggunaan inferensi lokal (misalnya di Raspberry Pi atau Orange Pi), trade-off kecepatan & ukuran dengan sedikit penurunan akurasi biasanya bisa diterima.
Kesimpulan
- Quantization 4-bit memang bisa berpengaruh ke akurasi, tapi dengan varian yang tepat, dampaknya bisa diperkecil.
- Jika butuh akurasi maksimal, pakai varian Q4_K_M atau bahkan format quantization dengan bit lebih tinggi (misalnya 8-bit).
- Untuk aplikasi ringan, Q4_0 tetap menarik karena sangat ringan dan cepat walau dengan akurasi lebih rendah.
✅ INT4 ≈ Q4
✅ INT8 ≈ Q8
Tapi ada sedikit nuansa teknis. Mari kita jelaskan:
? Perbandingan Q4 / Q8 vs INT4 / INT8
|
Istilah |
Makna Umum |
Catatan Teknis |
|
INT4 |
Integer 4-bit (misalnya 0–15 atau -8 hingga 7) |
Biasanya merujuk ke format data mentah |
|
Q4 |
Quantized 4-bit |
Biasanya termasuk skala + nol-titik (scale + zero-point) |
|
INT8 |
Integer 8-bit (-128 s.d. 127) |
Representasi integer murni |
|
Q8 |
Quantized 8-bit |
Bisa berarti INT8 yang sudah dikalibrasi |
? Bedanya Secara Praktis
- ✅ INT4 / INT8: Hanya tipe data — belum tentu efisien atau akurat.
- ✅ Q4 / Q8: Biasanya sudah mengalami proses quantization (misalnya dengan teknik GPTQ, AWQ, QLoRA), sehingga:
- Sudah disesuaikan (kalibrasi skala/nol).
- Dapat digunakan langsung untuk inference.
- Sudah disesuaikan (kalibrasi skala/nol).
? Contoh dari Dunia Nyata
|
Format GGUF / llama.cpp |
Artinya |
|
Q4_0, Q4_K, Q4_K_M |
Berbagai varian quantized 4-bit (INT4) |
|
Q5_1, Q5_K |
Versi 5-bit quantized |
|
Q8_0 |
Versi quantized 8-bit |
⚠️ Q4 ≠ satu jenis saja — banyak varian seperti Q4_0, Q4_K, dsb. Beberapa lebih akurat, beberapa lebih ringan.
? Kesimpulan
- ✅ INT4 = Q4 secara umum → digunakan bergantian dalam konteks AI inference.
- ⚠️ Tapi Q4 lebih spesifik → sudah melewati kalibrasi & scaling.
- ✅ Kalau kamu melihat model "Q4" di Hugging Face atau llama.cpp, itu artinya model sudah siap inferensi dalam format 4-bit.